Обеспечение взаимодействия с ЭВМ на естественном языке (ЕЯ) является важнейшей задачей исследований по искусственному интеллекту (ИИ). Базы данных, пакеты прикладных программ и экспертные системы, основанные на ИИ, требуют оснащения их гибким интерфейсом для многочисленных пользователей, не желающих общаться с компьютером на искусственном языке. В то время как многие фундаментальные проблемы в области обработки ЕЯ (Natural Language Processing, NLP) еще не решены, прикладные системы могут оснащаться интерфейсом, понимающем ЕЯ при определенных ограничениях. Существуют два вида и, следовательно, две концепции обработки естественного языка:
Природа обработки естественного языка Обработка естественного языка - это формулирование и исследование компьютерно-эффективных механизмов для обеспечения коммуникации с ЭВМ на ЕЯ. Объектами исследований являются:
Задача исследований - создание компьютерно-эффективных моделей коммуникации на ЕЯ. Именно такая постановка задачи отличает NLP от задач традиционной лингвистики и других дисциплин, изучающих ЕЯ, и позволяет отнести ее к области ИИ. Проблемой NLP занимаются две дисциплины: лингвистика и когнитивная психология. Традиционно лингвисты занимались созданием формальных, общих, структурных моделей ЕЯ, и поэтому отдавали предпочтение тем из них, которые позволяли извлекать как можно больше языковых закономерностей и делать обобщения. Практически никакого внимания не уделялось вопросу о пригодности моделей с точки зрения компьютерной эффективности их применения. Таким образом, оказалось, что лингвистические модели, характеризуя собственно язык, не рассматривали механизмы его порождения и распознавания. Хорошим примером тому служит порождающая грамматика Хомского, которая оказалась абсолютно непригодной на практике в качестве основы для компьютерного распознавания ЕЯ. Задачей же когнитивной психологии является моделирование не структуры языка, а его использования. Специалисты в этой области также не придавали большого значения вопросу о компьютерной эффективности. Различаются общая и прикладная NLP. Задачей общей NLP является разработка моделей использования языка человеком, являющихся при этом компьютерно-эффективными. Основой для этого является общее понимание текстов, как это подразумевается в работах Чарняка, Шенка, Карбонелла и др. Несомненно, общая NLP требует огромных знаний о реальном мире, и большая часть работ сосредоточена на представлении таких знаний и их применении при распознавании поступающего сообщения на ЕЯ. На сегодняшний день ИИ еще не достиг того уровня развития, когда для решения подобных задач в большом объеме использовались бы знания о реальном мире, и существующие системы можно называть лишь экспериментальными, поскольку они работают с ограниченным количеством тщательно отобранных шаблонов на ЕЯ. Прикладная NLP занимается обычно не моделированием, а непосредственно возможностью коммуникации человека с ЭВМ на ЕЯ. В этом случае не так важно, как введенная фраза будет понята с точки зрения знаний о реальном мире, а важно извлечение информации о том, чем и как ЭВМ может быть полезной пользователю (примером может служить интерфейс экспертных систем). Кроме понимания ЕЯ, в таких системах важно также и распознавание ошибок и их коррекция. Основная проблема обработки естественного языка Основной проблемой NLP является языковая неоднозначность. Существуют разные виды неоднозначности:
Центральная проблема как для общей, так и для прикладной NLP - разрешение такого рода неоднозначностей - решается с помощью перевода внешнего представления на ЕЯ в некую внутреннюю структуру. Для общей NLP такое превращение требует набора знаний о реальном мире. Так, для анализа фразы Jack took the bread from the supermarket shelf, paid for it, and left и для корректного ответа на такие вопросы, как What did Jack pay for? , What did Jack leave? и Did Jack have the bread with him when he left? необходимы знания о супермаркетах, процессах покупки и продажи и некоторые другие. Прикладные системы NLP имеют преимущество перед общими, т.к. работают в узких предметных областях. К примеру, системе, используемой продавцами в магазинах по продаже компьютеров, не нужно ”раздумывать” над неоднозначностью слова terminals в вопросе How many terminals are there in the order? . Тем не менее, создание систем, имеющих возможность общения на ЕЯ в широких областях, возможно, хотя пока результаты далеки от удовлетворительных. Технологии анализа естественного языка Под технологией анализа ЕЯ подразумевается перевод некоторого выражения на ЕЯ во внутреннее представление. Фактически все системы анализа ЕЯ могут быть распределены на следующие категории: подбор шаблона (Pattern Matching), синтаксический анализ, семантические грамматики, анализ с помощью падежных фреймов, “жди и смотри” (Wait And See), словарный экспертный (Word Expert), коннекционистский, “скользящий” (Skimming) анализ. Ниже пойдет речь о некоторых наиболее распространенных методах, описанных в статье. Подбор шаблона. Сущность данного подхода состоит в интерпретации ввода в целом, а не в интерпретации смысла и структуры его отдельных составляющих на более низком уровне. При использовании этого метода происходит сравнение уже имеющихся в системе шаблонов-образцов с текстом, поступившим на вход. Обычно шаблоны представлены в виде простого списка соответствий между классами высказываний и интерпретациями. Иногда они дополнены семантическими элементами или другими компонентами более высокого уровня. По такому принципу работает система Элиза , имитирующая диалог с психотерапевтом. В действительности система ничего не понимает, а лишь поддерживает диалог, сравнивая реплики пациента с шаблонами и присвоенными им соответствующими ответными репликами, такими, как:
В результате Элиза способна вести такой диалог:
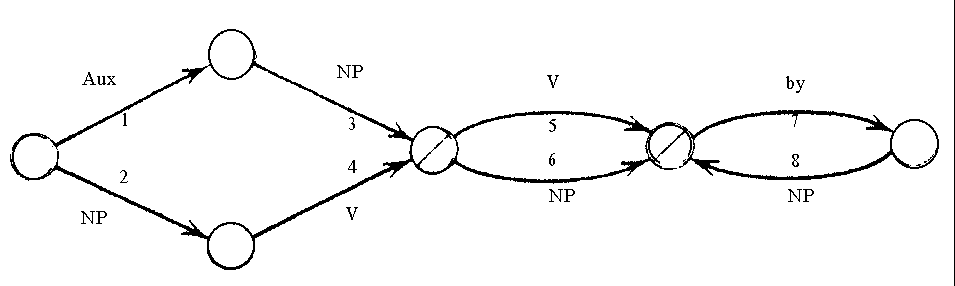
Синтаксический анализ . При использовании синтаксического анализа происходит интерпретация отдельных частей высказывания, а не всего высказывания в целом. Обычно сначала производится полный синтаксический анализ, а затем строится внутренне представление введенного текста, либо производится интерпретация. Деревья анализа и свободно-контекстные грамматики . Большинство способов синтаксического анализа реализовано в виде деревьев. Одна из простейших разновидностей - свободно-контекстная грамматика, состоящая из правил типа S=NP+VP или VP=V+NP и полагающая, что левая часть правила может быть заменена на правую без учета контекста. Свободно-контекстная грамматика широко используется в машинных языках, и с ее помощью созданы высокоэффективные методы анализа. Недостаток этого метода - отсутствие запрета на грамматически неправильные фразы, где, например, подлежащее не согласовано со сказуемым в числе. Для решения этой проблемы необходимо наличие двух отдельных, параллельно работающих грамматик: одной - для единственного, другой - для множественного числа. Кроме того, необходима своя грамматика для пассивных предложений и т.д. Семантически неправильное предложение может породить огромное количество вариантов разбора, из которых один будет превращен в семантическую запись. Всё это делает количество правил огромным и, в свою очередь, свободно-контекстные грамматики непригодными для NLP. Трансформационная грамматика . Трансформационная грамматика была создана с учетом упомянутых выше недостатков и более рационального использования правил ЕЯ, но оказалась непригодной для NLP. Трансформационная грамматика создавалась Хомским как порождающая, что, следовательно, делало очень затруднительным обратное действие, т.е. анализ. Расширенная сеть переходов . Расширенная сеть переходов была разработана Бобровым (Bobrow), Фрейзером (Fraser) и во многом Вудсом (Woods) как продолжение идей синтаксического анализа и свободно-контекстных грамматик в частности. Она представляет собой узлы и направленные стрелки, “расширенные” (т.е. дополненные) рядом тестов (правил), на основании которых выбирается путь для дальнейшего анализа. Промежуточные результаты записываются в ячейки (регистры). Ниже приводится пример такой сети, позволяющей анализировать простые предложения всех типов (включая пассив), состоящие из подлежащего, сказуемого и прямого дополнения, таких, как The rabbit nibbles the carrot (Кролик грызет морковь) . Обозначения у стрелок означают номер теста, а также либо признаки, аналогичные применяемым в свободно-контекстных грамматиках ( NP ), либо конкретные слова (by). Тесты написаны на языке LISP и представляют собой правила типа если условие=истина, то присвоить анализируемому слову признак Х и записать его в соответствующую ячейку.
Разберем алгоритм работы сети на вышеприведенном примере. Анализ начинается слева, т. е. с первого слова в предложении. Словосочетание the rabbit проходит тест, который выясняет, что оно не является вспомогательным глаголом ( Aux , стрелка 1), но является именной группой ( NP , стрелка 2). Поэтому the rabbit кладется в ячейку Subj, и предложение получает признак TypeDeclarative , т.е. повествовательное , и система переходит ко второму узлу. Здесь дополнительный тест не требуется, поскольку он отсутствует в списке тестов, записанных на LISP. Следовательно, слово, стоящее после the rabbit - т. е. nibbles - глагол-сказуемое (обозначение V на стрелке), и nibbles записывается в ячейку с именем V . Перечеркнутый узел означает, что в нем анализ предложения может в принципе закончиться. Но в нашем примере имеется еще и дополнение the carrot , так что анализ продолжается по стрелке 6 (выбор между стрелками 5 и 6 осуществляется снова с помощью специального теста), и словосочетание the carrot кладется в ячейку с именем Obj . На этом анализ заканчивается (последний узел был бы использован в случае анализа такого пассивного предложения, как The carrot was nibbled by the rabbit ). Таким образом, в результате заполнены регистры (ячейки) Subj , Type , V и Obj , используя которые, можно получить какое-либо представление (например, дерево). Расширенная сеть переходов имеет свои недостатки:
Семантические грамматики . Анализ ЕЯ, основанный на использовании семантических грамматик, очень похож на синтаксический, с той разницей, что вместо синтаксических категорий используются семантические. Естественно, семантические грамматики работают в узких предметных областях. Примером служит система Ladder , встроенная в базу данных американских судов. Ее грамматика содержит записи типа: S <present> the <attribute> of <ship> <present> what is|[can you] tell me <ship> the <shipname>|<classname> class ship Такая грамматика позволяет анализировать такие запросы, как Can you tell me the class of the Enterprise? ( Enterprise - название корабля). В данной системе анализатор составляет на основе запроса пользователя запрос на языке базы данных. Недостатки семантических грамматик состоят в том, что, во-первых, необходима разработка отдельной грамматики для каждой предметной области, а во-вторых, они очень быстро увеличиваются в размерах. Способы исправления этих недостатков - использование синтаксического анализа перед семантическим, применение семантических грамматик только в рамках реляционных баз данных с абстрагированием от общеязыковых проблем и комбинация нескольких методов (включая собственно семантическую грамматику). Анализ с помощью падежных фреймов . С созданием падежных фреймов связан большой скачок в развитии NLP. Они приобрели популярность после работы Филлмора “Дело о падеже”. На сегодняшний день падежные фреймы - один из наиболее часто используемых методов NLP, т.к. он является наиболее компьютерно-эффективным при анализе как снизу вверх (от составляющих к целому), так и сверху вниз (от целого к составляющим). Падежный фрейм состоит из заголовка и набора ролей (падежей), связанных определенным образом с заголовком. Фрейм для компьютерного анализа отличается от обычного фрейма тем, что отношения между заголовком и ролями определяется семантически, а не синтаксически, т.к. в принципе одному и то же слово может приписываться разные роли, например, существительное может быть как инструментом действия, так и его объектом. Общая структура фрейма такова: [Заголовочный глагол [падежный фрейм агент: <активный агент, совершающий действие> объект: <объект, над которым совершается действие> инструмент: <инструмент, используемый при совершении действия> реципиент: <получатель действия - часто косвенное дополнение> направление: <цель (обычно физического) действия> место: <место, где совершается действие> бенефициант: <сущность, в интересах которой совершается действие> коагент: <второй агент, помогающий совершать действие> ]] Например, для фразы Иван дал мяч Кате падежный фрейм выглядит так: [Давать [падежный фрейм агент: Иван объект: мяч реципиент: Катя] [грам время: прош залог: акт] ] Существуют обязательные, необязательные и запрещенные падежи. Так, для глагола разбить обязательным будет падеж объект - без него высказывание будет незаконченным. Место и коагент будут в данном примере необязательными падежами, а направление и реципиент - запрещенными. Часто в NLP бывает полезным использовать семантическое представление в как можно более канонической форме. Наиболее известным способом такой репрезентации являются метод концептуальных зависимостей , разработанный Шенком для глаголов действия. Он заключается в том, что каждое действие представлено в виде одного или более простейших действий. Например, для предложений Иван дал мяч Кате (1) и Катя взяла мяч у Ивана (2), различающихся синтаксически, но оба обозначающих акт передачи, могут быть построены следующие репрезентации с использованием простейшего действия Atrans , применяющегося в грамматике концептуальных зависимостей:
С помощью такого представления легко выявляются сходства и различия фраз. Для облегчения анализа также используется деление роли на лексический маркер и заполнитель. Так, для роли объект может быть установлен маркер прямое дополнение , для роли источник - маркер вида <маркер-из>=из|от| ... В общем анализ текста с помощью падежных фреймов состоит из следующих шагов:
Преимущества использования падежных фреймов таковы:
Определенную трудность при анализе представляет вариативность одного и того же запроса. Например, на вход системы, управляющей зачислением и перераспределением учащихся на курсах разных специальностей, может поступить запрос типа Переведите Петрова, если это возможно, с математики на, скажем, экономику . Наиболее легко такие трудности преодолеваются при использовании падежных фреймов. Правило, сформулированное Карбонеллом и Хейзом, гласит: “Следует пропускать неизвестные введенные элементы до тех пор, пока не будет найден падежный маркер; пропущенные элементы следует анализировать с учетом незаполненных падежей, используя только семантику”. Наряду с проблемой распознавания текста существует и проблема поддержания интерактивного диалога. При этом возникают дополнительные особенности, характерные для диалогов, а именно:
Кроме того, пользователи систем с естественно-языковым интерфейсом стараются выражаться как можно короче, что в ряде случаев также затрудняет анализ. Использование падежных фреймов, а именно слияние текущего фрейма с предыдущим, обеспечивает восстановление эллипсиса. Таким образом, процесс разработки систем, обеспечивающих понимание ЕЯ, требует создание механизмов, отличных от традиционных способов представлений ЕЯ, а системы с естественно-языковыми интерфейсами применяются только в узких предметных областях.
Encyclopaedia of Artificial Intelligence. Entry Natural Language Understanding , pp. 660-677 Поделитесь этой записью или добавьте в закладки |
Полезные публикации |
|
|
|
 Главная
Главная|
| Разрешается частичное копирование контента в виде анонса при условии размещения прямой ссылки на источник. |
© 2006-2026 «Claw.RU» © 2010-2026 «Рефератики.РФ» |